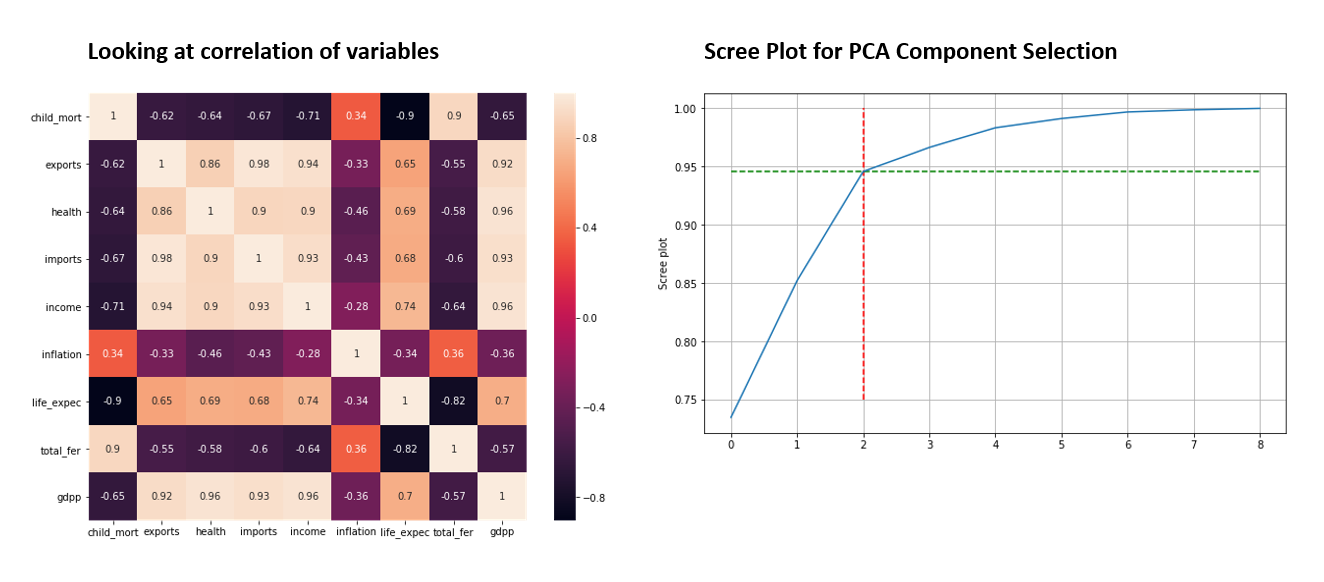
Use PCA before clustering
Reducing dimensionality helps improve clustering performance while retaining essential data patterns.

HELP International, a humanitarian NGO, has raised $10 million for poverty alleviation and disaster relief. To allocate this funding strategically and effectively, this project analyzes socio-economic and health indicators to identify countries most in need.
By examining income levels, poverty rates, and child mortality statistics, the analysis categorizes countries into priority tiers for aid distribution. The study follows the World Bank classification of low-income and lower-middle-income countries, prioritizing 22 nations with both extreme poverty and high child mortality rates. These findings will assist the NGO’s leadership in making data-driven funding decisions to maximize impact.

The Steps I Took |
The Strategy I Followed |
Tools I Used |
|
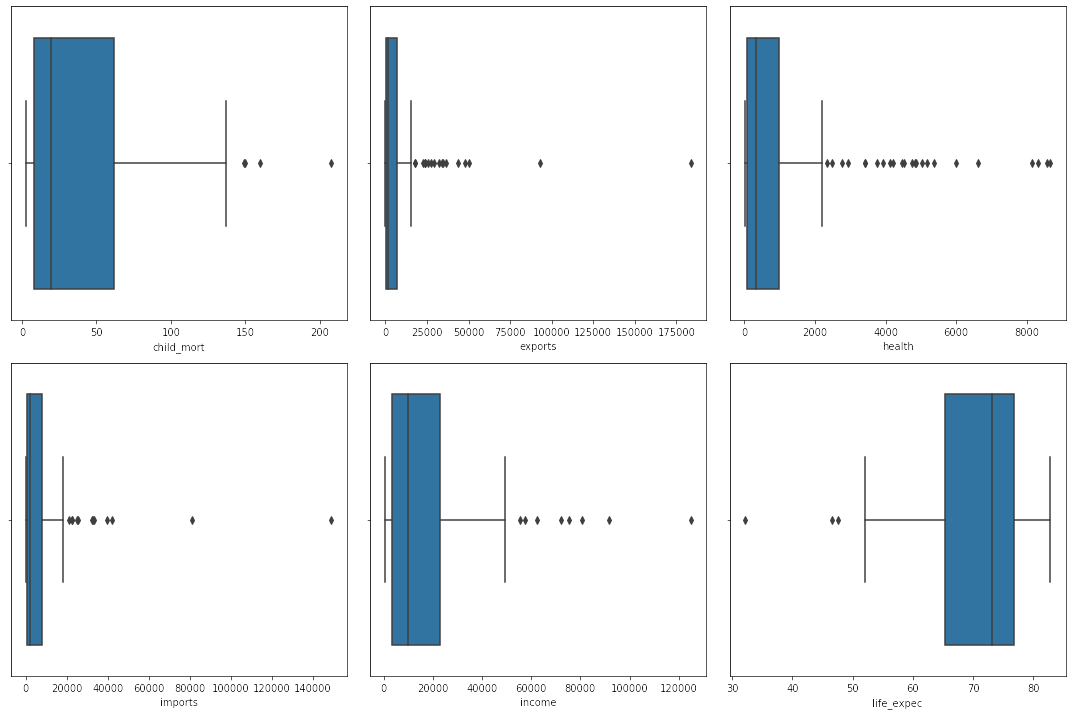
✔ Performed basic exploratory data analysis (EDA) to understand feature distributions. |
✔ Gained an understanding of data distribution – Explored patterns before applying PCA and clustering. |
|
⚠️ High dimensionality made clustering less effective – PCA was applied to simplify the dataset while preserving information.
⚠️ Choosing the optimal number of clusters – Used Elbow Method & Silhouette Score for accurate selection.
⚠️ Interpreting clusters – Required domain knowledge to assign meaningful labels.
According to the World Bank classification, countries with a Gross National Income (GNI) per capita between $1,026 and $3,995 are considered lower-middle-income countries, while those below $1,025 fall into the low-income category. These low-income nations typically have a high percentage of the population living under the poverty line and face significant development challenges.
Using the available dataset, the analysis identified 42 countries that fall under the above-average GNI threshold of $1,274.
Afghanistan, Angola, Benin, Burkina Faso, Burundi, Cameroon, Central African Republic, Chad, Comoros, Congo (Dem. Rep.), Congo (Rep.), Côte d'Ivoire, Eritrea, Gabon, Gambia, Ghana, Guinea, Guinea-Bissau, Haiti, Iraq, Kenya, Kiribati, Lesotho, Liberia, Madagascar, Malawi, Mali, Mauritania, Mozambique, Niger, Nigeria, Pakistan, Rwanda, Senegal, Sierra Leone, Sudan, Tanzania, Timor-Leste, Togo, Uganda, Yemen, Zambia.
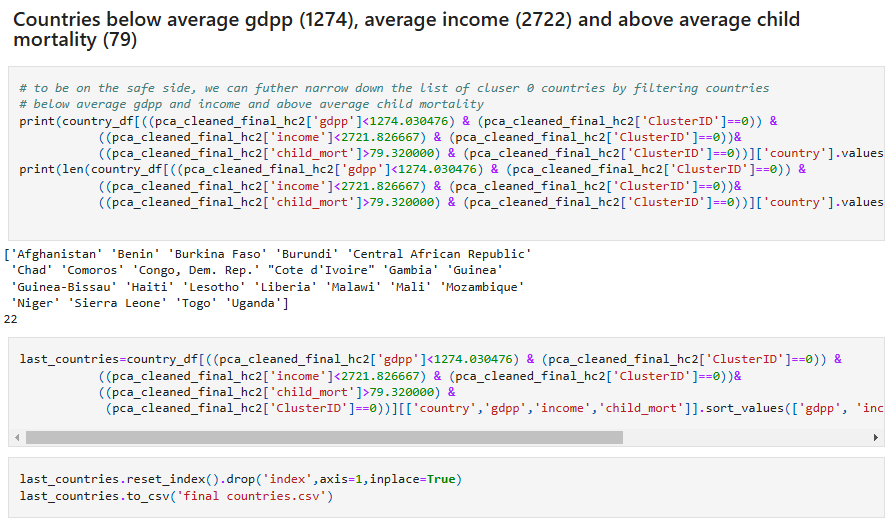
However, if prioritization is required due to budget constraints or the need for more targeted intervention, additional filtering was applied. This identified 22 countries with both below-average income (≤ $1,274) and child mortality rates exceeding 79 children per 1,000 live births, making them the most urgent candidates for aid allocation.
Afghanistan, Benin, Burkina Faso, Burundi, Central African Republic, Chad, Comoros, Congo (Dem. Rep.), Côte d'Ivoire, Gambia, Guinea, Guinea-Bissau, Haiti, Lesotho, Liberia, Malawi, Mali, Mozambique, Niger, Sierra Leone, Togo, Uganda.
✔ 42 countries meet the criteria for financial aid based on low-middle and low-income classification.
✔ 22 countries were identified as critical due to extreme poverty and high child mortality rates.
✔ This prioritization can help HELP International distribute its $10 million aid budget more effectively by focusing on the most vulnerable populations.
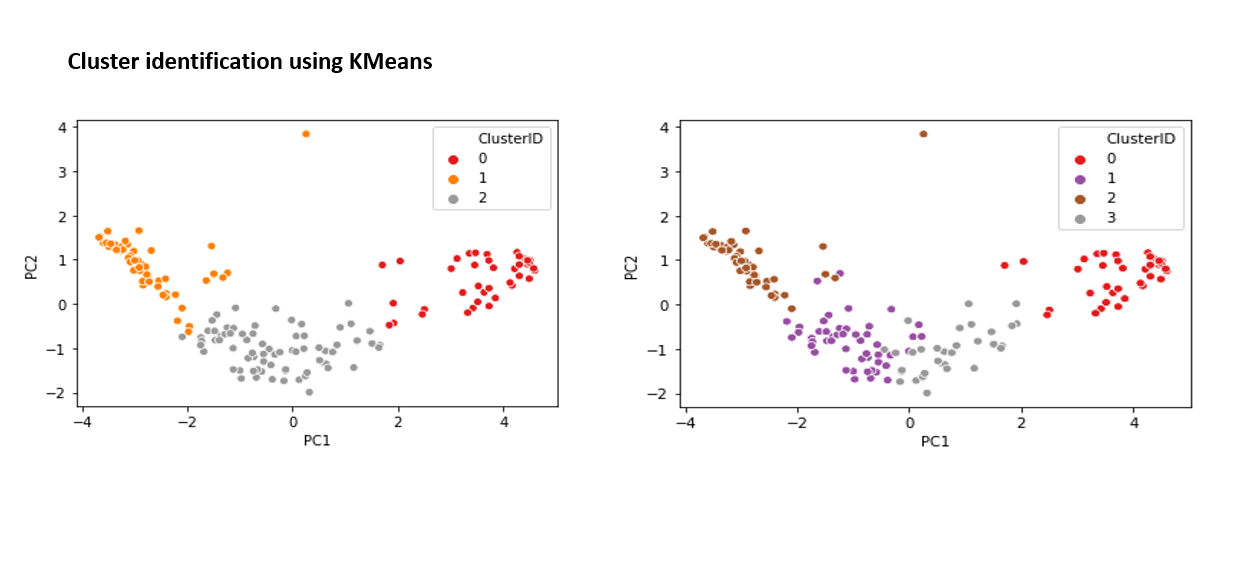
Reducing dimensionality helps improve clustering performance while retaining essential data patterns.
Choose the optimal number of clusters using Elbow Method & Silhouette Score – Avoid overfitting or under-segmentation by selecting the most meaningful cluster count.
Interpret cluster characteristics meaningfully – Assign descriptive labels based on real-world insights, making segmentation useful for decision-making.
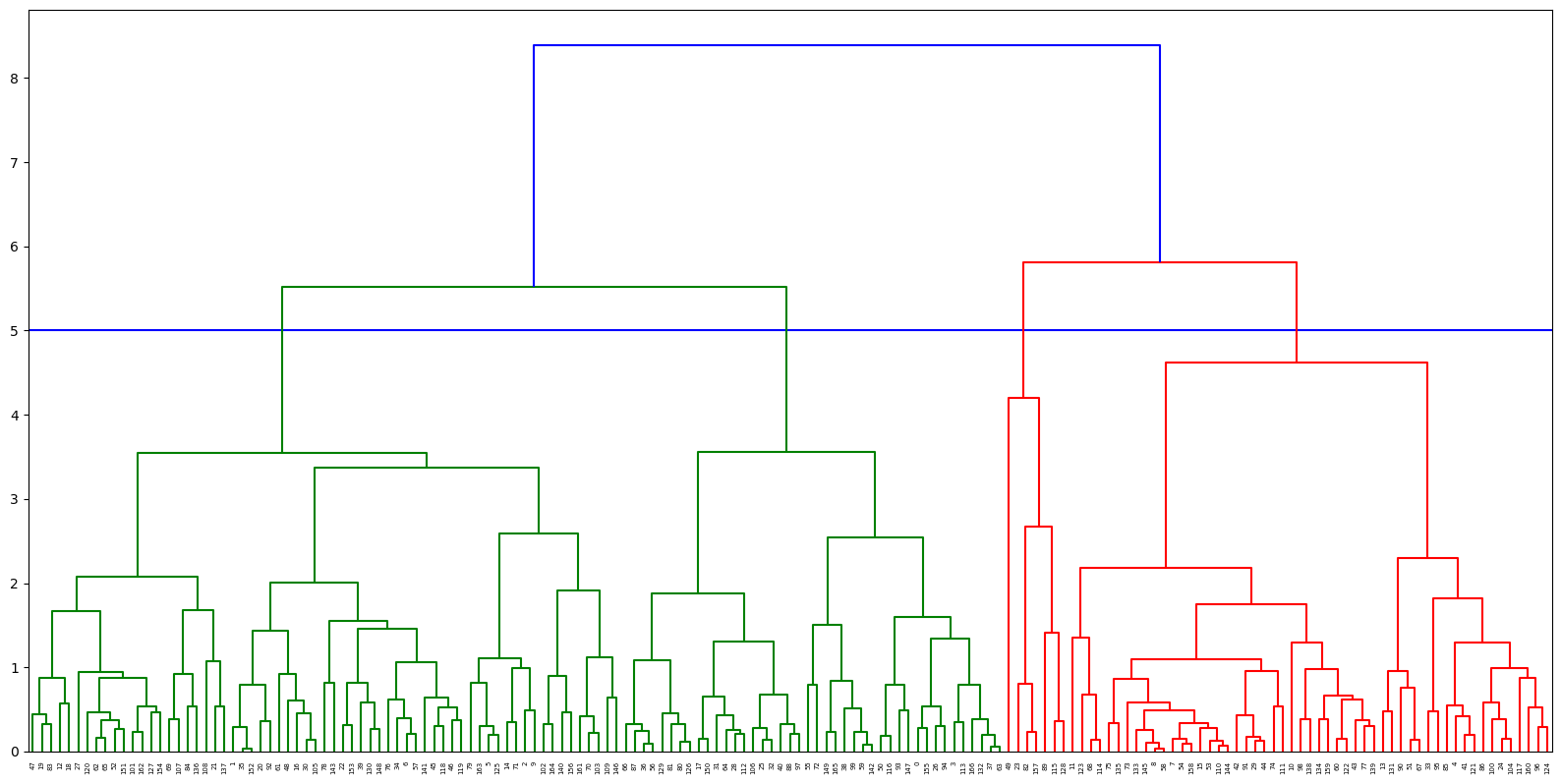
While K-Means worked best in this case, testing alternative methods like Hierarchical Clustering can provide additional insights.
Visualize clusters using PCA-transformed data – Helps in understanding group separations and cluster relationships effectively.
Leverage clustering insights for targeted decision-making – Whether applied to marketing, finance, or social initiatives, clustering should guide resource allocation and policy planning.
This project successfully demonstrated how Principal Component Analysis (PCA) and Clustering techniques can be used to segment data efficiently while preserving important information. By leveraging dimensionality reduction and unsupervised learning, we were able to identify meaningful groups and optimize the clustering process.
The insights derived from this analysis can be applied in various domains, including customer segmentation, market analysis, financial risk assessment, and social development projects. The recommendations provided ensure that clustering models remain effective, interpretable, and applicable for decision-making.
By continuously refining these techniques and incorporating domain expertise, organizations can unlock deeper insights, enhance predictive capabilities, and improve data-driven strategies.
Code: Github Repository